Diagnosing Problems
If your Intel hardware RAID system is beeping this almost always indicates a hardware fault. Faults need to be investigated and corrected promptly. The easiest way to do this is to always set up your servers or systems with the correct monitoring software when you install the system. This means that you do not need to find additional utilities or software when your system is in a potentially dangerous state.
Contact Support
Always contact Stone Support for warranty service and advice. We can help you when your system has a problem and help protect your data. The steps below are provided as a guide and are not exhaustive. They are based on a system with an Intel / Avago / Broadcom / LSI hardware RAID controller or module.
If your System is Beeping
- Note any warnings displayed onscreen
- Use the RAID monitoring software to check the health of your Logical or Virtual Drives (Virtual drives are the actual RAID arrays themselves, as opposed to each single physical drive).
- Partially Degraded RAID6 arrays have had a single drive failure.
- Degraded RAID5 arrays have also had a single drive failure.
- Degraded RAID6 arrays have had two drive failures.
- A RAID array marked as Failed has had more drive failures than it can tolerate.
- In this situation, please contact Stone for additional support. We will take you through a process to try and recover the situation, by marking any Failed (or "Unconfigured Bad") drives as good and then scanning the controller for disk configurations that it can import from failed drives (known as foreign configurations). This is a temporary measure to bring the RAID array back online until replacement disks can be fitted. Usually, the last disk to fail can be brought back online and re-integrated into a failed RAID array as long as the drive is still workable.
- If the last hard drive to fail is no longer detected, or cannot be brought back into the RAID configuration due to the number of defects or problems with the drive, then the RAID array has failed and the data will need to be restored from backups when the RAID array has been reconstructed.
- Check your servers Hot-Swap drive bays (if fitted) and look for any drive bays with an amber or flashing amber/orange LED. Amber usually means that the drive has failed; Amber/Orange usually means that the drive in that bay is being rebuilt. An Amber/Orange drive may not be the faulty drive in the system if that drive was previously unused and marked as a "Hot-Spare".
- If All Virtual drives are still healthy, and no single disks ("JBOD") are missing (for example, you can still access all disk volumes through File Explorer or Disk Management) then your system could have faults which include:
- A controller fault, such as a memory fault or battery failure (check the RAID log for details)
- Problems detected in a patrol read, such as bad blocked which indicated that a drive is about to fail - again check the RAID log for details but also check each physical disks Media Error Count and Predictive Failure Count.
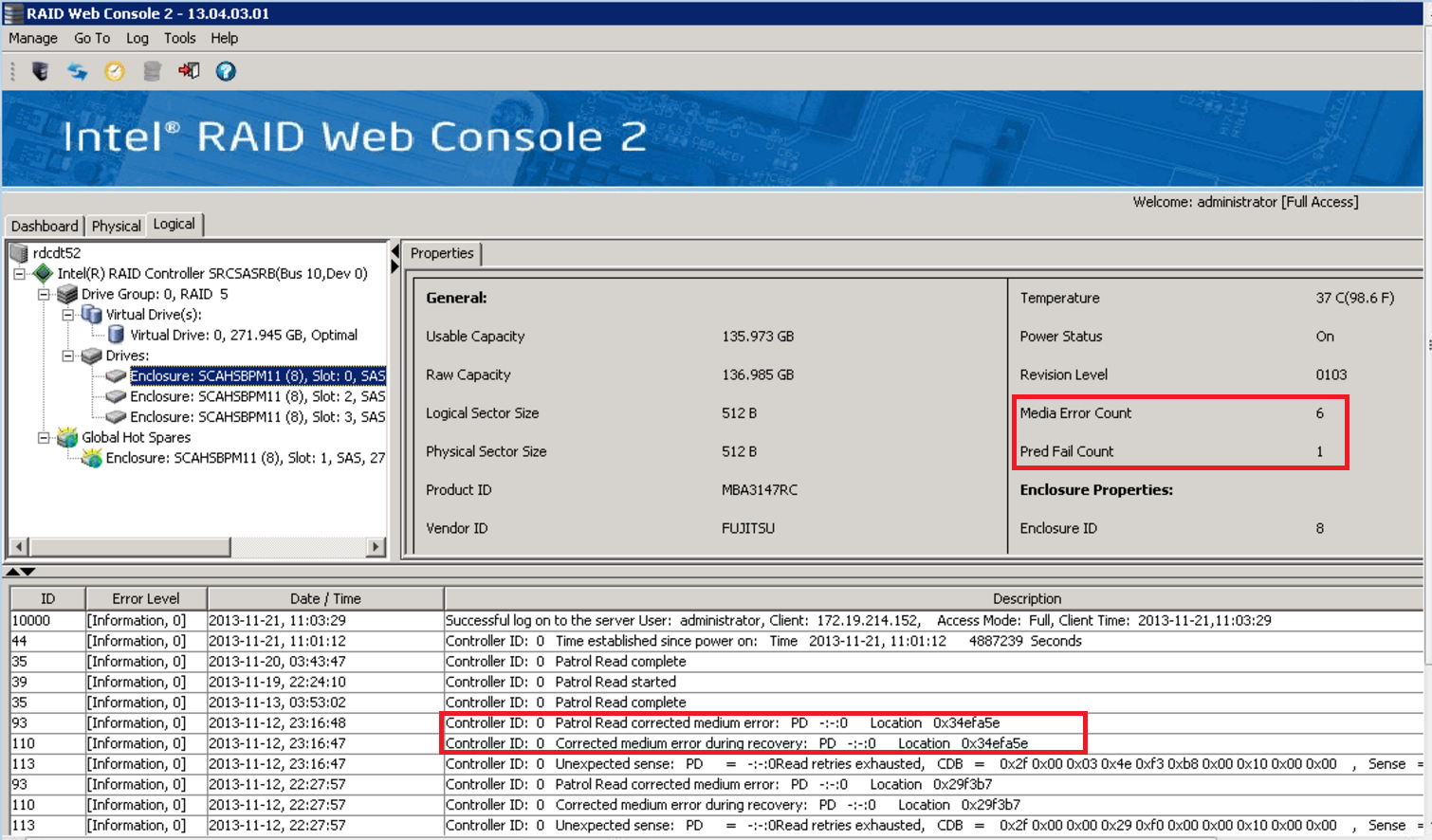
- If the RAID system appears to be completely healthy, double check that the beeping noise is actually a RAID event. For example, some server systems may beep when a Power Fault is detected. Or, a UPS in the cabinet may have a problem. Check your servers warning triangle and ensure that it is green.

- Try silencing the RAID alarm. If the beeping persists, you have not got a RAID system fault.
Remember: An Amber/Orange drive bay light may not necessarily indicate that that drive is faulty - it could be that the drive in that bay was previously available as a Hot-Spare and the system is rebuilding onto it. Check for the presence of other amber lights or other "Unconfigured Bad" drives in the RAID console.
Silencing the Alarm
If the RAID system beep is distracting your users, the alarm may be temporarily silenced. To do this:
- Open up the Physical or Logical Tab of Intel RWC2 / LSI MSM
- Right hand click on the controller.
- Then, left click on Silence Alarm
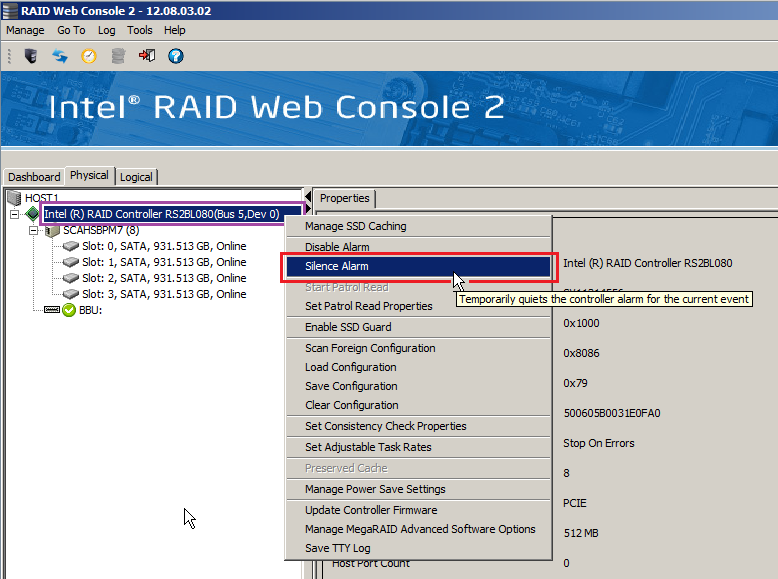
Important: Do not use the feature to Disable the Alarm, as this will prevent you from hearing the audible alarm if there are future failures, or for example the rebuild process fails to complete.
Replacing Hard Drives
Your Stone warranty service will carry out this for you, however some pointers are given below:
Do:
- Identify hard drives first before replacing them. Use the Drive location feature if you have hot-swap drive bays fitted.
- Right hand click on the drive you want to identify, then left click on Start Locating Drive
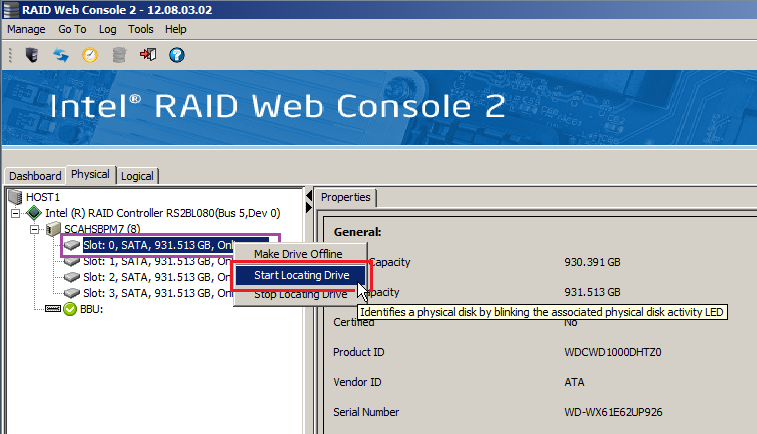
- If your system doesn't include hot-swap drive bays, then record the Port or Slot number of the failed drive, as well as the serial numbers of either the failed drive, or, if this is not accessible, record the serial numbers of the remaining drives for elimination purposes. You can then work out which is the failed drive.
- Always hot-swap drives where possible. Do not shut the system down unless necessary - hot-swapping allows the rebuild process to start automatically if configured.
- Always replace drives with equal or greater capacity and equal or greater performance.
- It is recommended that you don't use Advance Format drives if the RAID array was built on non-Advance format drives.
- Always ensure that the rebuild process starts and then completes.
- If the rebuild process doesn't start automatically (this is the default on older controllers such as the Intel SRCSASRB and Intel SRCSATAWB) mark the replacement drive as a global hot-spare. This will trigger the rebuild process.
Applies to:
- Servers and workstations with a hardware Intel / Broadcom RAID controller or module
