Managing Hard Drive Failures in Servers
When a hard drive fails in a server, it is normally recommended that you obtain a warranty replacement hard drive and do not re-use the old hard drive in the RAID array. When a hard drive has been marked as failed, it is normally due to a defect such as a large number of bad blocks or other malfunction. While the hard drive may come back online it should not be relied upon.
The only exception to the rule of not re-using a hard drive is where the drive failure has left the RAID array in a failed state. This should only happen when you are using a RAID 0 array (which is not recommended) or if the system has already suffered a drive failure. In this scenario, when the array has failed, it is recommended to attempt to bring the last failed drive back online. If you succeed in bringing the RAID online, please take a full backup as soon as possible but ensure that you do not overwrite your last previous full backup. A bare metal or system state backup should be used. When this has been completed, the drive should then be replaced and the RAID array rebuilt, and then the system restored.
In the event of any hard drive or RAID system failure please contact Stone Support for warranty service. If your system is outside of warranty, we may be able to offer an out of warranty chargeable repair.
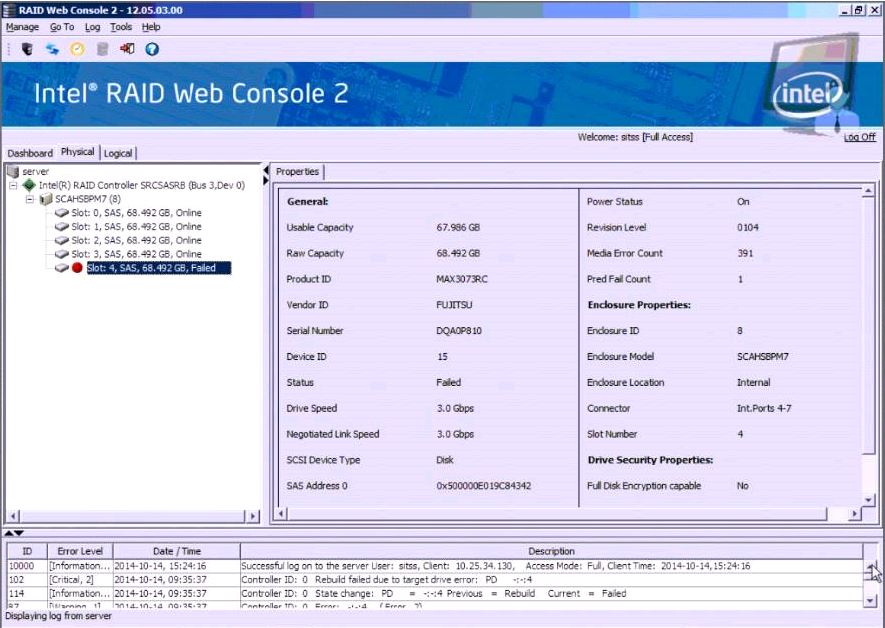
Example of a Faulty Drive
The RAID Web Console example below shows a drive with media errors (bad blocks) as well as a SMART predictive failure count. This drive should be replaced. Note that some low end software RAID controllers (such as the Intel ESRT-2 controller) don't preserve media error counts or predictive failure counts between reboots.
Applies to:
- Server and workstation systems running Firmware or Hardware RAID